AWS GlueのData Catalogは、Apache Hive Metastore互換のカタログとして知られています。そこで、AWS GlueのData Catalogの実装をHive Metastoreを起点に解き明かし、その周辺のテクノロジーであるHiveとSparkの動きもついでに理解したいと思います。このリポジトリを読むことで、任意のデータソースにおいて更新されたデータをGlueでクロールし、それをData Catalogとして保存し、データを管理する一連の方法が理解できます。
さて、Hive ですが、Hadoop クラスター上で SQL 互換言語を提供します。HiveとSparkの主な違いは、以下表に書かれた通りで、それぞれAWS GlueやAthenaにも使われている大変興味深いテクノロジーです。なお、純粋な Hive 環境が手元になかったため、今回はSpark セッションの開始時に Hive にて EnableHiveSupport オプションを使用することで、処理結果をストレージに保存する方法を通じて、AWS Glueの実装を一緒に解き明かしましょう。
The AWS Glue Data Catalog is known to be compatible with the Apache Hive Metastore. Therefore, we aim to uncover the implementation of the AWS Glue Data Catalog starting from the Hive Metastore, and additionally understand the workings of the surrounding technologies, Hive and Spark. By reading this repository, you will grasp how to crawl updated data from any data source using Glue, save it as a Data Catalog, and manage the data.
Now, regarding Hive, it provides an SQL-compatible language on a Hadoop cluster. The main differences between Hive and Spark are listed in the table below. Both are highly intriguing technologies also used in AWS Glue and Athena. Since there was no pure Hive environment available, we will use the EnableHiveSupport option at the start of a Spark session to save the processing results to storage, thus uncovering the implementation of AWS Glue together.
| Apache Hive | Presto / Spark | |
|---|---|---|
| Intermediate result | Write to Storage | Write to Memory |
| Performance | Slow | Fast |
| Use cases | Large data aggregations | Interactive queries and quick data exploration |
| Checkpoint of Failure | Resume from intermediate data saved in storage | Start over |
See also URL below:
https://github.com/developer-onizuka/AzureDataFactory#4-difference-between-hive-presto-and-spark https://medium.com/@sarfarazhussain211/metastore-in-apache-spark-9286097180a4
今回はデータソースをMongoDBとして、Sparkを動かすことにします。MongoDBの使い方とそこに入れるデータについては以下のURLを参照ください。
This time, we will use MongoDB as the data source and run Spark. See URL below:
Spark セッションの開始時に Hive にて EnableHiveSupport オプションを使用すると、Spark が既存の Hive インストールとシームレスに統合し、Hive のMetadataとストレージ機能を活用できるようになります。 Hive で Spark を使用すると、Spark API を使用して Hive テーブルに格納されたデータの読み取りと書き込みができます。これにより、Hive の機能と利点を活用しながら、Spark のパフォーマンスとスケーラビリティの最適化が可能となります。
Enabling hive support, allows Spark to seamlessly integrate with existing Hive installations, and leverage Hive’s metadata and storage capabilities. When using Spark with Hive, you can read and write data stored in Hive tables using Spark APIs. This allows you to take advantage of the performance optimizations and scalability benefits of Spark while still being able to leverage the features and benefits of Hive.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("myapp") \
.master("local") \
.config("spark.executor.memory", "1g") \
.config("spark.mongodb.input.uri","mongodb://172.17.0.2:27017") \
.config("spark.mongodb.output.uri","mongodb://172.17.0.2:27017") \
.config("spark.jars.packages","org.mongodb.spark:mongo-spark-connector_2.12:3.0.0") \
.enableHiveSupport() \
.getOrCreate()
EnableHiveSupport() を使用せずに Spark セッションを作成した場合、spark.sql.catalogImplementation の出力は None になります。 Spark SQL のデフォルトは、in-memroy (つまり、non-Hive) カタログです。
If you create the spark session without enableHiveSupport(), then the output of spark.sql.catalogImplementation must be None. Spark SQL defaults is in-memory (non-Hive) catalog.
conf = spark.sparkContext.getConf()
print("# spark.app.name = ", conf.get("spark.app.name"))
print("# spark.master = ", conf.get("spark.master"))
print("# spark.executor.memory = ", conf.get("spark.executor.memory"))
print("# spark.sql.warehouse.dir = ", conf.get("spark.sql.warehouse.dir"))
print("# spark.sql.catalogImplementation = ", conf.get("spark.sql.catalogImplementation"))
# spark.app.name = myapp
# spark.master = local
# spark.executor.memory = 1g
# spark.sql.warehouse.dir = file:/home/jovyan/spark-warehouse
# spark.sql.catalogImplementation = hive
df = spark.read.format("mongo") \
.option("database","test") \
.option("collection","products") \
.load()
DataFrame は、DataFrame の内容を具体化し、Hive Metastore内のデータへのポインターを作成する saveAsTable コマンドを使用して、永続テーブルとして保存できます (つまり、Spark の DataFrame から Hive テーブルを作成します)。Metastoreも自動的に作成されるため、マネージド テーブルと呼ばれます。 saveAsTable() の代わりに save() を使用する場合は、自分でMetastoreを作成し、テーブルをMetastoreに関連付ける必要があります。 save() は、DataFrame のParquetファイルを「products_new」ディレクトリに作成しますが、metastore_db ディレクトリは作成しないことを意味します。自分で行う必要があるため、アンマネージ テーブルと呼ばれます。 #4-1も参照してください。 Hive Metastoreでは、Spark セッションが再起動された後でも、永続テーブルがまだ存在している限り、永続テーブルに対するクエリを実行できます。
DataFrames can be saved as persistent tables (ie. Create a Hive Table from a DataFrame in Spark) using the saveAsTable command which will materialize the contents of the DataFrame and create a pointer to the data in the Hive metastore. It is called as a Managed Table, because metastore is also created automatically. If you use the save() instead of saveAsTable(), then you have to create metastore by yourself and associate tables with metastore.
The save() means that it creates parquet files for the DataFrame in the directory of "products_new" but it does not create metastore_db directory. You have to do it by yourself, so it is called an Unmanaged Table. See also #4-1.
The Hive metastore allows to query to the persistent table, even after spark session is restared as long as the persistent tables still exist.
df.write.mode("overwrite").saveAsTable("products_new")
spark.sql("DESCRIBE EXTENDED products_new").show(100,100)
+----------------------------+--------------------------------------------------------------+-------+
| col_name| data_type|comment|
+----------------------------+--------------------------------------------------------------+-------+
| ListPrice| double| null|
| MakeFlag| int| null|
| ModelName| string| null|
| ProductID| int| null|
| ProductName| string| null|
| ProductNumber| string| null|
| StandardCost| double| null|
| SubCategoryID| int| null|
| _id| struct<oid:string>| null|
| | | |
|# Detailed Table Information| | |
| Database| default| |
| Table| products_new| |
| Owner| jovyan| |
| Created Time| Thu May 09 13:42:10 UTC 2024| |
| Last Access| UNKNOWN| |
| Created By| Spark 3.2.1| |
| Type| MANAGED| | <---
| Provider| parquet| |
| Statistics| 13447 bytes| |
| Location| file:/home/jovyan/HiveMetastore/spark-warehouse/products_new| |
| Serde Library| org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe| |
| InputFormat| org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat| |
| OutputFormat|org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat| |
+----------------------------+--------------------------------------------------------------+-------+
saveAsTable() ではなく save() でParquetファイルを作成する場合は、以下のように自分でParquetファイルとテーブルを関連付ける必要があります。
You have to associate between parquet files and table by yourself as like below, if you create parquet files by save() instead of saveAsTable():
df.write.mode("overwrite").save("products_new")
spark.sql("CREATE EXTERNAL TABLE external_products USING parquet LOCATION '/home/jovyan/HiveMetastore/products_new'")
spark.sql("DESCRIBE EXTENDED external_products").show(100,100)
+----------------------------+--------------------------------------------+-------+
| col_name| data_type|comment|
+----------------------------+--------------------------------------------+-------+
| ListPrice| double| null|
| MakeFlag| int| null|
| ModelName| string| null|
| ProductID| int| null|
| ProductName| string| null|
| ProductNumber| string| null|
| StandardCost| double| null|
| SubCategoryID| int| null|
| _id| struct<oid:string>| null|
| | | |
|# Detailed Table Information| | |
| Database| default| |
| Table| external_products| |
| Created Time| Thu May 09 13:28:22 UTC 2024| |
| Last Access| UNKNOWN| |
| Created By| Spark 3.2.1| |
| Type| EXTERNAL| | <---
| Provider| parquet| |
| Location|file:/home/jovyan/HiveMetastore/products_new| |
+----------------------------+--------------------------------------------+-------+
Spark は、#4 または #4-1 の後、現在のディレクトリにMetastore (metastore_db) を自動的に作成し、デフォルトの Apache Derby (完全に Java で実装されたオープン ソース リレーショナル データベース) でデプロイされます。また、Spark テーブル (本質的にはParquetファイルのコレクション) を保存するために、spark.sql.warehouse.dir によって構成されたディレクトリも作成します。この場合のみ、Hive テーブルが作成されるときは、デフォルトでカレントディレクトリ内のspar-warehouse ディレクトリになります。デフォルトの形式は「parquet」なので、指定しない場合はそれが想定されます。
Spark automatically creates metastore (metastore_db) in the current directory, deployed with default Apache Derby (an open source relational database implemented entirely in Java) after #4 or #4-1. And also creates a directory configured by spark.sql.warehouse.dir to store the Spark tables (essentially it's a collection of parquet files), which defaults to the directory spark-warehouse in the current directory when Hive Table is created only for the case of #4. The default format is "parquet" so if you don’t specify it, it will be assumed.
https://towardsdatascience.com/notes-about-saving-data-with-spark-3-0-86ba85ca2b71
Hive Metastoreは、Spark セッションが再開された場合でも、Parquetファイルと saveAsTable() で作成されたデータベース間の関連付けを保持します。
つまり、S3 上の Parquet ファイルをデータベースとして扱うために、Parquet ファイルとデータベースの関係を定義します。これは Hive Metastore と呼ばれ、AWS Glue のデータ カタログ のデータベース (一種のワークスペース) に保存されます。 Amazon Athena などの一部のサービスは、Parquet ファイルを直接ではなく、このデータ カタログを参照して、データ分析のために SQL を使用してデータベースにクエリを実行できます。
つまり、Metastoreは、「非構造化データをテーブルの列、名前、データ型にマッピングして、直接の SQL テーブルとして扱えるようにするにはどうすればよいですか?」という質問が成り立つものになります。
The Hive metastore preserves an association between the parquet file and a database created with saveAsTable(), even if a spark session is restarted.
In other words, Define the relationship between the Parquet file and the database in order to treat Parquet files in S3 as a database. This is called Hive Metastore, and it is stored in a database (a kind of workspaces) in AWS Glue's Data Catalog. Some services such a Amazon Athena can refer to this Data Catalog to query the database with SQL for data analysis, instead of Parquet files directly.
In short, a metastore is a thing which can answer the question of "How do I map the unstructured data to table columns, names and data types which will allow to me to treat as a straight up SQL table?"

%ls -l
total 24
-rw-r--r-- 1 jovyan users 672 May 7 05:10 derby.log
drwxr-sr-x 5 jovyan users 4096 May 7 05:10 metastore_db/
drwxr-sr-x 3 jovyan users 4096 May 7 05:08 spark-warehouse/
-rw-r--r-- 1 jovyan users 5891 May 7 05:22 Untitled.ipynb
drwsrwsr-x 1 jovyan users 4096 May 7 05:10 work/
%ls -l spark-warehouse/products_new
total 16
-rw-r--r-- 1 jovyan users 13401 May 7 06:07 part-00000-ff9a9aac-0f2a-4b4d-a856-417c2cd411fd-c000.snappy.parquet
-rw-r--r-- 1 jovyan users 0 May 7 06:07 _SUCCESS
%cat derby.log
----------------------------------------------------------------
Mon May 07 05:10:06 UTC 2024:
Booting Derby version The Apache Software Foundation - Apache Derby - 10.14.2.0 - (1828579): instance a816c00e-0187-f49d-f849-0000042485f8
on database directory /home/jovyan/metastore_db with class loader jdk.internal.loader.ClassLoaders$AppClassLoader@5ffd2b27
Loaded from file:/usr/local/spark-3.2.1-bin-hadoop3.2/jars/derby-10.14.2.0.jar
java.vendor=Ubuntu
java.runtime.version=11.0.13+8-Ubuntu-0ubuntu1.20.04
user.dir=/home/jovyan
os.name=Linux
os.arch=amd64
os.version=5.4.0-139-generic
derby.system.home=null
Database Class Loader started - derby.database.classpath=''
{kind=link}
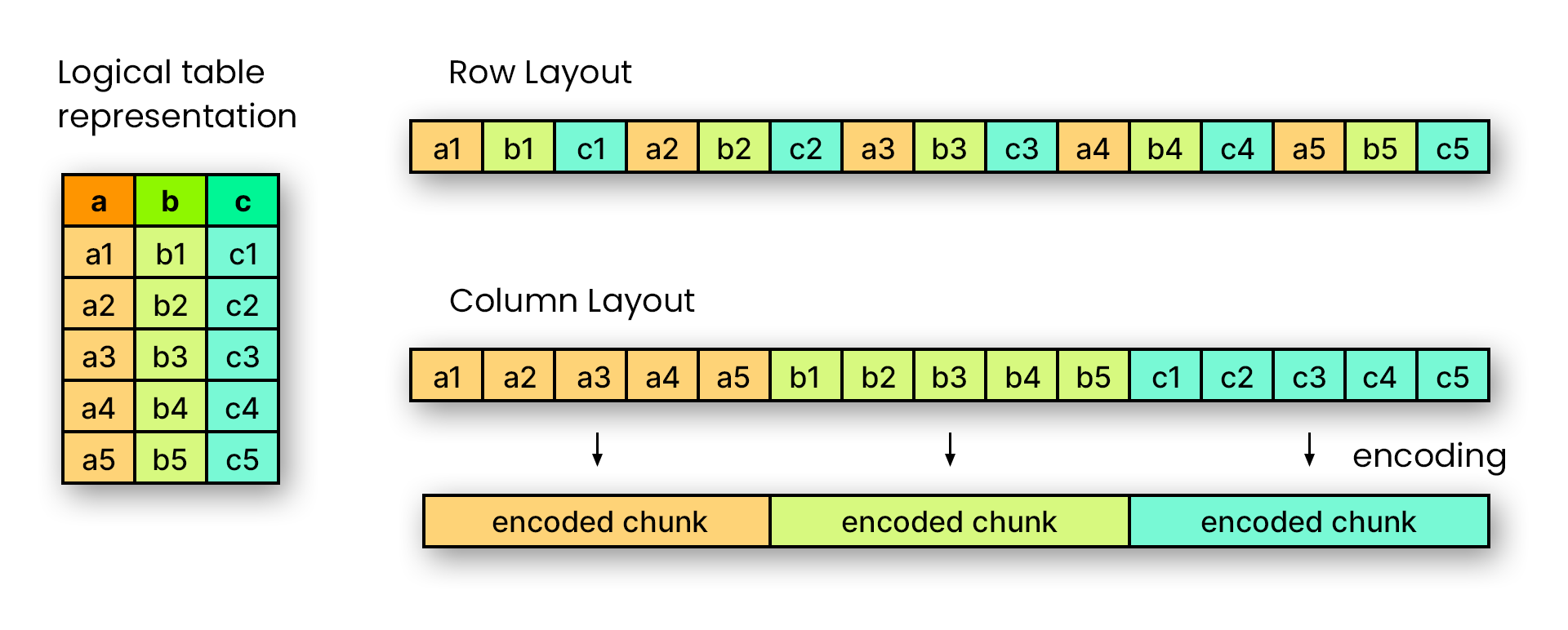
列形式のファイル形式である Apache Parquet は、他の形式よりもはるかに効率的かつコスト効率よくコンピューターで読み取ることができるため、ビッグ データ、分析、データ レイク ストレージにとって理想的なファイル形式となっています。 Parquet の主な利点は、パフォーマンスが高く、圧縮が効率的で、業界標準であることです。
As a columnar file format, Apache Parquet can be read by computers much more efficiently and cost-effectively than other formats, making it an ideal file format for big data, analytics, and data lake storage. Some of Parquet’s main benefits are that it is high performance, has efficient compression, and is the industry standard.
spark.stop() を実行してセッションを再度作成した後でも、再度クエリを実行できます。
You can query again even after spark.stop() and creating the session again.
spark.sql("SELECT * FROM products_new WHERE StandardCost > 2000").show()
+---------+--------+---------+---------+----------------+-------------+------------+-------------+--------------------+
|ListPrice|MakeFlag|ModelName|ProductID| ProductName|ProductNumber|StandardCost|SubCategoryID| _id|
+---------+--------+---------+---------+----------------+-------------+------------+-------------+--------------------+
| 3578.27| 1| Road-150| 749|Road-150 Red, 62| BK-R93R-62| 2171.2942| 2|{6456f3d06fcaf22f...|
| 3578.27| 1| Road-150| 750|Road-150 Red, 44| BK-R93R-44| 2171.2942| 2|{6456f3d06fcaf22f...|
| 3578.27| 1| Road-150| 751|Road-150 Red, 48| BK-R93R-48| 2171.2942| 2|{6456f3d06fcaf22f...|
| 3578.27| 1| Road-150| 753|Road-150 Red, 56| BK-R93R-56| 2171.2942| 2|{6456f3d06fcaf22f...|
| 3578.27| 1| Road-150| 752|Road-150 Red, 52| BK-R93R-52| 2171.2942| 2|{6456f3d06fcaf22f...|
+---------+--------+---------+---------+----------------+-------------+------------+-------------+--------------------+
mongoDB が更新された場合は、spark.read.format("mongo") を再度使用し、df.write.mode("overwrite").saveAsTable("products_new") を使用してそれを DataFrame にロードする必要があります。これにより、必要に応じて Hive Metastoreを更新できるようになります。
If mongoDB is updated, then you should load it into DataFrame with spark.read.format("mongo") again and df.write.mode("overwrite").saveAsTable("products_new") so that the Hive Metastore can be updated if needed.
But how often do you update the Hive Metastore? You can learn it from the blog of (Real-Time) Hive Crawling.
root@efe0e844a026:/# cat <<EOF >products2.csv
ProductID,ProductNumber,ProductName,ModelName,MakeFlag,StandardCost,ListPrice,SubCategoryID
1000,BK-R19B-99,"Road-750 Black, 99",Road-750,1,3000.00,3000.00,2
EOF
root@efe0e844a026:/# mongoimport --host="localhost" --port=27017 --db="test" --collection="products" --type="csv" --file="products2.csv" --headerline
df = spark.read.format("mongo") \
.option("database","test") \
.option("collection","products") \
.load()
df.write.mode("overwrite").saveAsTable("products_new")
%ls -l spark-warehouse/products_new
total 16
-rw-r--r-- 1 jovyan users 13506 May 7 10:56 part-00000-31f77afe-1dcd-43c7-ac11-7b82331bfeab-c000.snappy.parquet
-rw-r--r-- 1 jovyan users 0 May 7 10:56 _SUCCESS
spark.sql("SELECT * FROM products_new WHERE StandardCost > 2000").show()
+---------+--------+---------+---------+------------------+-------------+------------+-------------+--------------------+
|ListPrice|MakeFlag|ModelName|ProductID| ProductName|ProductNumber|StandardCost|SubCategoryID| _id|
+---------+--------+---------+---------+------------------+-------------+------------+-------------+--------------------+
| 3578.27| 1| Road-150| 750| Road-150 Red, 44| BK-R93R-44| 2171.2942| 2|{6457837b2b6b00c5...|
| 3578.27| 1| Road-150| 751| Road-150 Red, 48| BK-R93R-48| 2171.2942| 2|{6457837b2b6b00c5...|
| 3578.27| 1| Road-150| 752| Road-150 Red, 52| BK-R93R-52| 2171.2942| 2|{6457837b2b6b00c5...|
| 3578.27| 1| Road-150| 753| Road-150 Red, 56| BK-R93R-56| 2171.2942| 2|{6457837b2b6b00c5...|
| 3578.27| 1| Road-150| 749| Road-150 Red, 62| BK-R93R-62| 2171.2942| 2|{6457837b2b6b00c5...|
| 3000.0| 1| Road-750| 1000|Road-750 Black, 99| BK-R19B-99| 3000.0| 2|{645783d4913c74c8...|
+---------+--------+---------+---------+------------------+-------------+------------+-------------+--------------------+
Data Source (mongoDB in this example)
--> DataFrame in Spark
--> saveAsTable() in Spark
--> parquet files & metastore (Data Catalog)
--> Analytics (by some AWS services such as AWS Quick Insight etc...)
今回、AWS Glue の Data Catalog が、Apache Hive Metastore互換のカタログであることを、この一連の手順から理解できました。また、AWS Glue は、Spark を使用してETL ジョブとしてデータソースからデータをインポートするプロセスの背後でMetastoreを作成するマネージドサービスと考えることができるでしょう。
This time, through this series of steps, we understood that the AWS Glue Data Catalog is compatible with the Apache Hive Metastore. Additionally, AWS Glue can be considered a managed service that creates a metastore behind the process of importing data from data sources as an ETL job using Spark.